

Unifying Heterogeneity: Ingesting Multi-Source First-Party Data for Cookieless Retargeting
Problem Statement
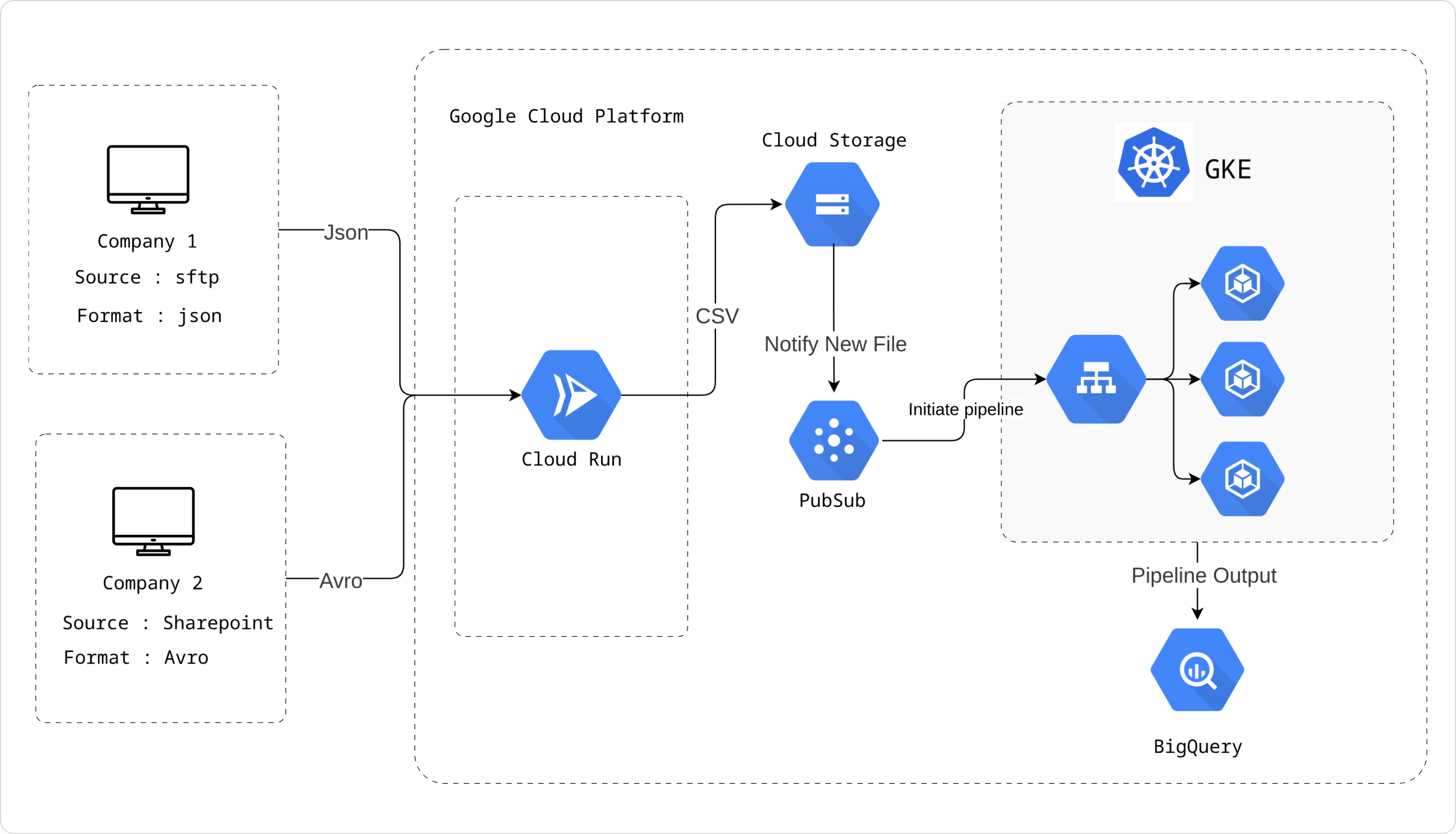
Amidst rising user privacy concerns, major players such as Apple and Google have initiated restrictions on third-party browser cookies. Third-party cookies compromise user privacy by enabling cross-site tracking without explicit consent. The inevitable deprecation of third-party cookies emphasise the importance of relying on first-party data, which is privacy compliant. The client needed to transition from processing third-party cookie data to utilizing first-party data for retargeting advertising campaigns. In addressing this shift, they encountered two challenges: - The first-party data across companies is in different schemas and is also stored in various systems (e.g., SharePoint, S3 buckets) - Each schema requires distinct processing logic.
Client Info
A leading marketing agency, specialized in retargeting campaigns.
Outcomes
Time to onboard a new customer reduced from 2 months to 1 week.
Resilient system that can read and process large files (upto 100GB).
Sales team differentiated their pitch to onboard new customers citing the pilot success stories.
How did BeautifulCode do it?
We studied diverse data systems such as SharePoint, S3 buckets, API endpoints, and SFTP, through which companies share their first-party data. The goal was to extract data from these systems and place it into company-specific buckets for isolation and security compliance. Integrating each new system posed challenges, especially in understanding unique processes like authentication and downloading. To address this, we thoroughly analyzed these systems and developed tailored libraries. We also built an easy to use interfaces to access these libraries for simpler integration with different data systems.
Cleansing and Transformation pipeline stages
Our data exists in various formats, including Avro, JSON, and CSV, among others. Each of these formats necessitates distinct data pipeline operations, such as cleaning and transformation, to be defined separately. To streamline this process, our strategy involves converting all these diverse data formats into a common CSV format. This uniformity allows us to run the data through the same pipeline efficiently. Additionally, this approach simplifies our optimization efforts, as we only need to focus on enhancing the processing of the CSV format, rather than tweaking the pipeline for every different format. This method not only standardizes our data processing but also significantly boosts efficiency and consistency across our operations.
The following are the different aspects of the solution
Abstract data connector framework
This framework allows for seamless data retrieval from various sources, including FTP, SharePoint, APIs, and different cloud storage platforms. It simplifies the process of integrating new data sources by providing a standard interface and handling authentication and authorization mechanisms.
Isolated Cloud Storage
Data from each customer is securely stored in separate cloud storage buckets, ensuring privacy and compliance with data regulations. Granular IAM policies are implemented to restrict access to specific data sets. The creation of buckets for individual customers and the assignment of detailed IAM policies to these buckets are orchestrated as infrastructure-as-code operations using Terraform.
Event-Driven Architecture
The data ingestion process is triggered by events, automatically initiating the data cleaning and transformation pipelines. This eliminates the need for manual intervention and ensures real-time data processing.
Configurable Pipelines
Every company's data has its own unique format and dimensions, making it challenging to create individual pipelines for each. Recognizing that this approach is not scalable, we introduced configurable pipelines, serving as flexible building blocks to compose new pipelines swiftly. This strategy not only accelerated the creation of pipelines but also enhances the overall flexibility.
Boosting Pipeline Performance
While Pandas excels at data analysis, it can struggle with massive datasets, often exceeding RAM limitations and causing performance bottlenecks. To overcome these challenges, we utilized DASK which was built on top of Pandas' API. DASK seamlessly scales data processing to multiple cores and even distributed clusters. DASK allows us to read data in chunks, parallelizing operations across available resources. This gave a performance boost to the pipelines, enabling us to handle large datasets with fewer machines.
Technologies Used
© 2025 BeautifulCode. All rights reserved.